1、部署 Helm - 什么是 Helm
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment 、 svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂, helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理。
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等)可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署。
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。 Helm 有两个重要的概念: chart 和 release。
chart是创建一个应用的信息集合,包括各种Kubernetes对象的配置模板、参数定义、依赖关系、文档说明等。chart是应用部署的自包含逻辑单元。可以将chart想象成 apt、yum 中的软件安装包。release是chart的运行实例,代表了一个正在运行的应用。当chart被安装到Kubernetes集群,就生成一个release。chart能够多次安装到同一个集群,每次安装都是一个release。
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示:
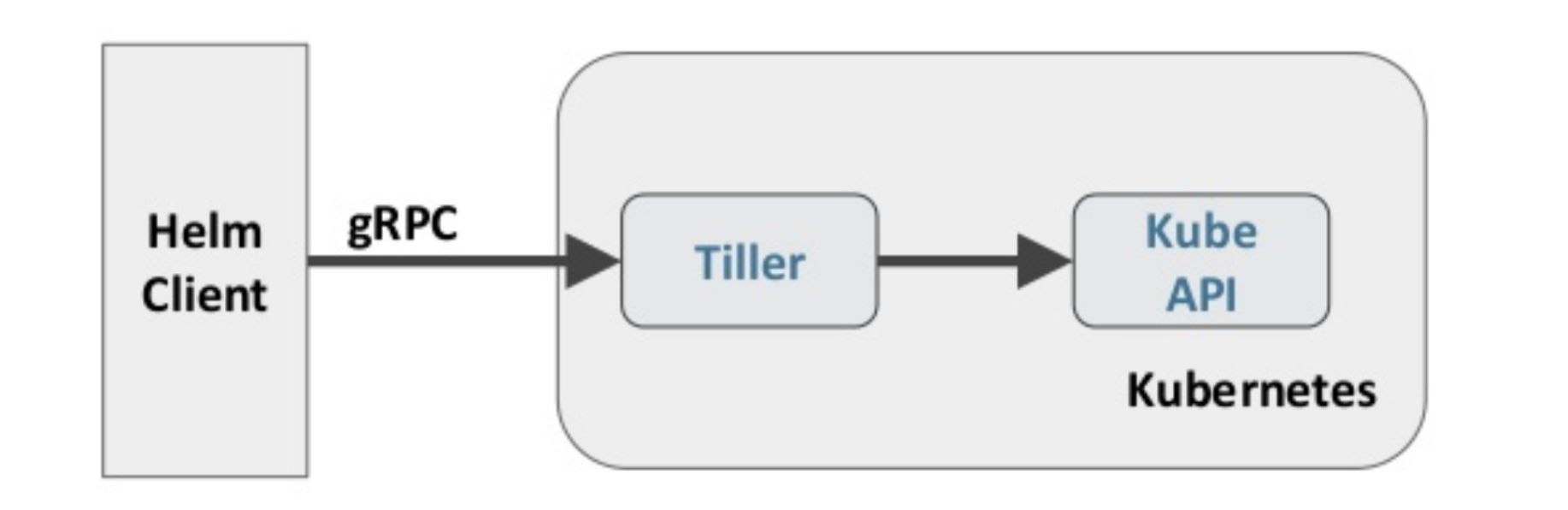
Helm 客户端负责 chart 和 release 的创建和管理以及和 Tiller 的交互。Tiller 服务器运行在 Kubernetes 集群中,它会处理 Helm 客户端的请求,与 Kubernetes API Server 交互。
Helm 部署
越来越多的公司和团队开始使用 Helm 这个 Kubernetes 的包管理器,我们也将使用 Helm 安装 Kubernetes 的常用组件。 Helm 由客户端命令 helm 令行工具和服务端 tiller 组成,Helm 的安装十分简单。 下载 helm 命令行工具到 master 节点 node1 的 /usr/local/bin 下,这里下载的 2.13.1 版本:
为了安装服务端 tiller,还需要在这台机器上配置好 kubectl 工具和 kubeconfig 文件,确保 kubectl 工具可以在这台机器上访问 apiserver 且正常使用。 这里的 node1 节点以及配置好了 kubectl。
因为 Kubernetes APIServer 开启了 RBAC 访问控制,所以需要创建 tiller 使用的 service account: tiller 并分配合适的角色给它。 详细内容可以查看 helm 文档中的 Role-based Access Control。 这里简单起见直接分配 cluster-admin 这个集群内置的 ClusterRole 给它。创建 rbac-config.yaml 文件:
👉 使用 Helm 时,需要注意以下几点:
- 为 chart 添加版本号,并保存每个版本的 values.yaml 文件,以便后续修改。
- 在使用 Helm 进行部署时,务必仔细检查 chart 的各个参数和配置,保证其正确性与安全性。
- 在使用 Helm 进行升级时,务必注意备份原有的 values.yaml 文件,以便回滚操作。同时,在升级时应该逐个参数检查,避免意外的变更。
tiller 默认被部署在 k8s 集群中的 kube-system 这个 namespace 下
Helm 自定义模板
Debug
- 若无法正常加载, 请点击查看 PDF 网页版本: 部署 Helm.pdf
2、使用 Helm 部署 dashboard
kubernetes-dashboard.yaml:
- 若无法正常加载, 请点击查看 PDF 网页版本: 使用 Helm 部署 dashboard.pdf
3、使用 Helm 部署 metrics-server
下文的 [prometheus 已经集成 不再单独部署]
从 Heapster 的 github (https://github.com/kubernetes/heapster) 中可以看到已经,Heapster 已经 DEPRECATED。这里是 Heapster 的 deprecation timeline。可以看出 Heapster 从 Kubernetes 1.12 开始将从 Kubernetes 各种安装脚本中移除。Kubernetes 推荐使用 metrics-server。我们这里也使用 helm 来部署 metrics-server。
metrics-server.yaml:
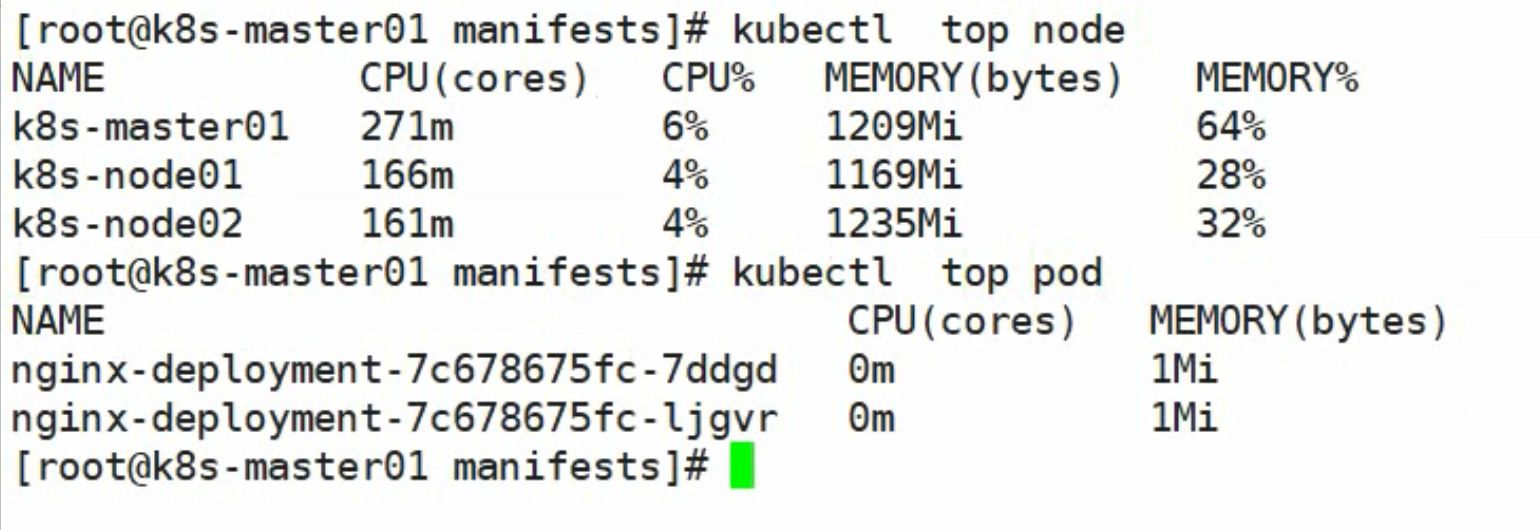
使用下面的命令可以获取到关于集群节点基本的指标信息:
| NAME | CPU(cores) | CPU% | MEMORY(bytes) | MEMORY% |
|---|---|---|---|---|
| node1 | 650m | 32% | 1276Mi | 73% |
| node2 | 73m | 3% | 527Mi | 30% |
| NAMESPACE | NAME | CPU(cores) | MEMORY(bytes) |
|---|---|---|---|
| ingress-nginx | nginx-ingress-controller-6f5687c58d-jdxzk | 3m | 142Mi |
| ingress-nginx | nginx-ingress-controller-6f5687c58d-lxj5q | 5m | 146Mi |
| ingress-nginx | nginx-ingress-default-backend-6dc6c46dcc-lf882 | 1m | 4Mi |
| kube-system | coredns-86c58d9df4-k5jkh | 2m | 15Mi |
| kube-system | coredns-86c58d9df4-rw6tt | 3m | 23Mi |
| kube-system | etcd-node1 | 20m | 86Mi |
| kube-system | kube-apiserver-node1 | 33m | 468Mi |
| kube-system | kube-controller-manager-node1 | 29m | 89Mi |
| kube-system | kube-flannel-ds-amd64-8nr5j | 2m | 13Mi |
| kube-system | kube-flannel-ds-amd64-bmncz | 2m | 21Mi |
| kube-system | kube-proxy-d5gxv | 2m | 18Mi |
| kube-system | kube-proxy-zm29n | 2m | 16Mi |
| kube-system | kube-scheduler-node1 | 8m | 28Mi |
| kube-system | kubernetes-dashboard-788c98d699-qd2cx | 2m | 16Mi |
| kube-system | metrics-server-68785fbcb4-k4g9v | 3m | 12Mi |
| kube-system | tiller-deploy-c4fd4cd68-dwkhv | 1m | 24Mi |
- 若无法正常加载, 请点击查看 PDF 网页版本: 使用 Helm 部署 metrics-server.pdf
4、部署 prometheus
相关地址信息
Prometheus GitHub 地址:https://github.com/coreos/kube-prometheus
组件说明
MetricServer:是 Kubernetes 集群资源使用情况的聚合器,收集数据给 Kubernetes 集群内使用,如kubectl,hpa,scheduler等。PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。NodeExporter:用于各 node 的关键度量指标状态数据。KubeStateMetrics:收集 Kubernetes 集群内资源对象数据,制定告警规则。Prometheus:采用 Pull 方式收集apiserver、scheduler、controller-manager、kubelet组件数据,通过 HTTP 协议传输。Grafana:是可视化数据统计和监控平台。
构建记录
修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana:
修改 prometheus-service.yaml,改为 nodepode:
修改 alertmanager-service.yaml,改为 nodepode:
Horizontal Pod Autoscaling
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者 Replica Set 中的 Pod 数量。
为了演示 HPA, 我们将使用一个基于 php-apache 镜像的定制 Docker 镜像, 里面会消耗大量CPU密集资源.
创建 HPA 控制器 - 相关算法的详情请参阅这篇文档:
增加负载,查看负载节点数目:
看到的效果是从
1个pod自动扩容到了10个Pod, 压力变小后Pod又变回一个
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup。
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现。
requests 要分配的资源,limits 为最高请求的资源值。可以简单理解为初始值和最大值。
资源限制 - 名称空间
I. 计算资源配额
II. 配置对象数量配额限制
III. 配置 CPU 和 内存 LimitRange
是一个补充, 按理说不应该放在名称空间下
如果容器没有设置的话 那么默认就会使用名称空间下的资源
default即limit的值defaultRequest即request的值。
如果一个Pod设置的资源限制(limit)高于命名空间中指定资源限制,那么Pod的资源限制将覆盖命名空间资源限制。同样,如果Pod的请求(request)高于命名空间资源请求,Pod的请求将覆盖命名空间资源请求。因此,Pod的资源限制和资源请求优先级最高,将覆盖命名空间的资源限制和请求。
访问 prometheus
prometheus 对应的 nodeport 端口为 30200,访问 http://MasterIP:30200。
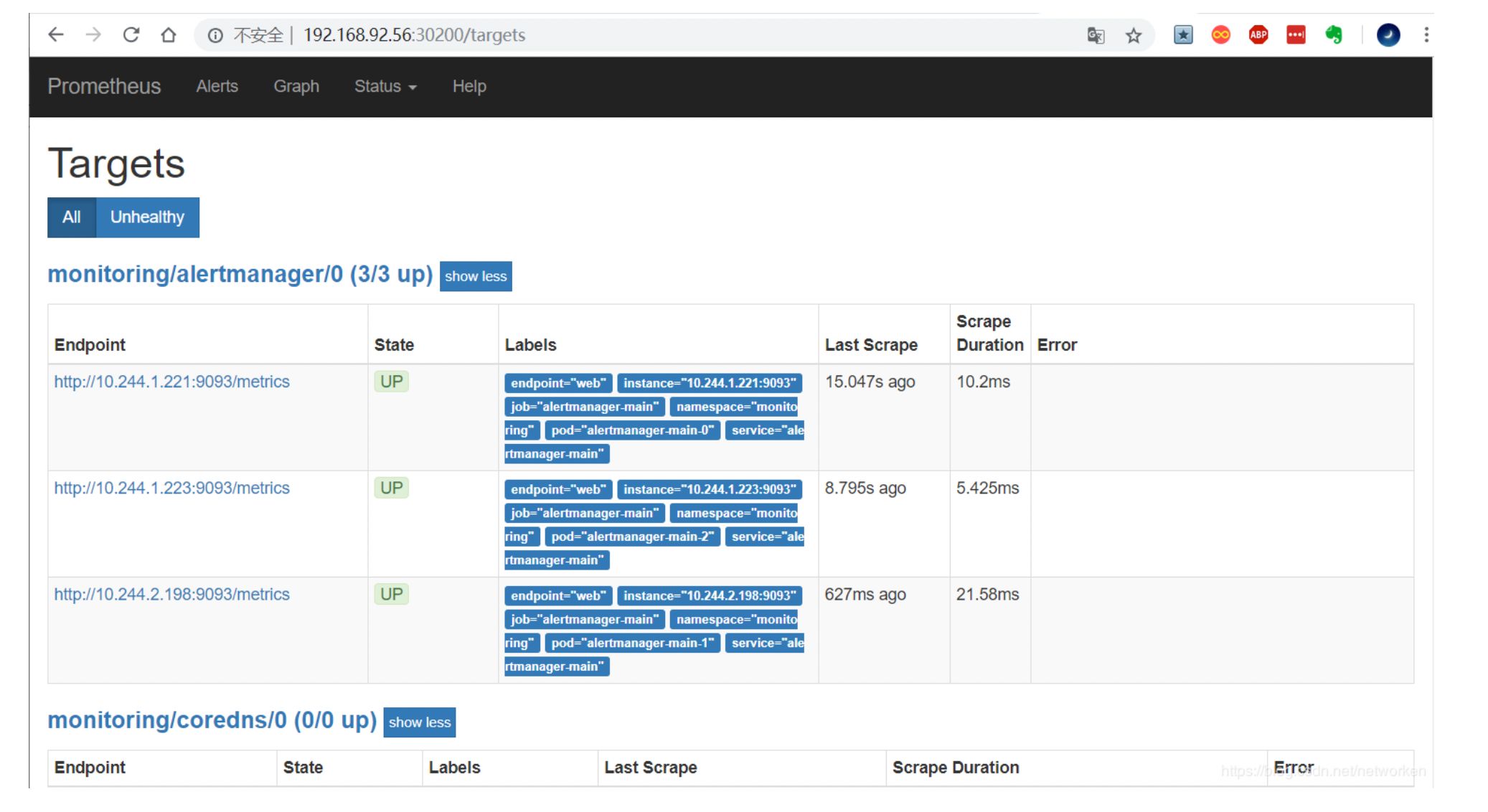
通过访问 http://MasterIP:30200/target 可以看到 prometheus 已经成功连接上了 k8s 的 apiserver。
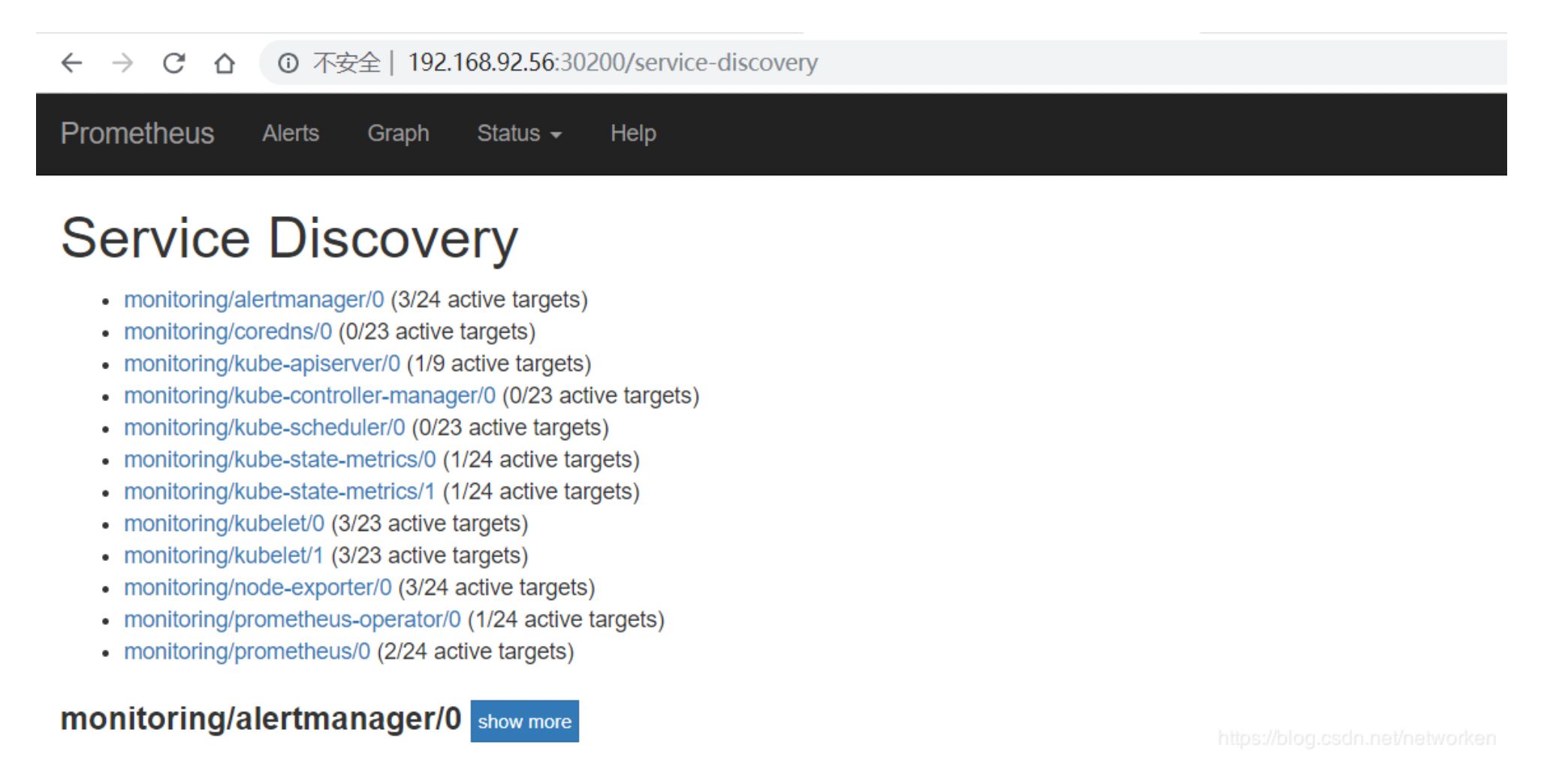
查看 service-discovery:
Prometheus 自己的指标:
prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况,查询条件如下:
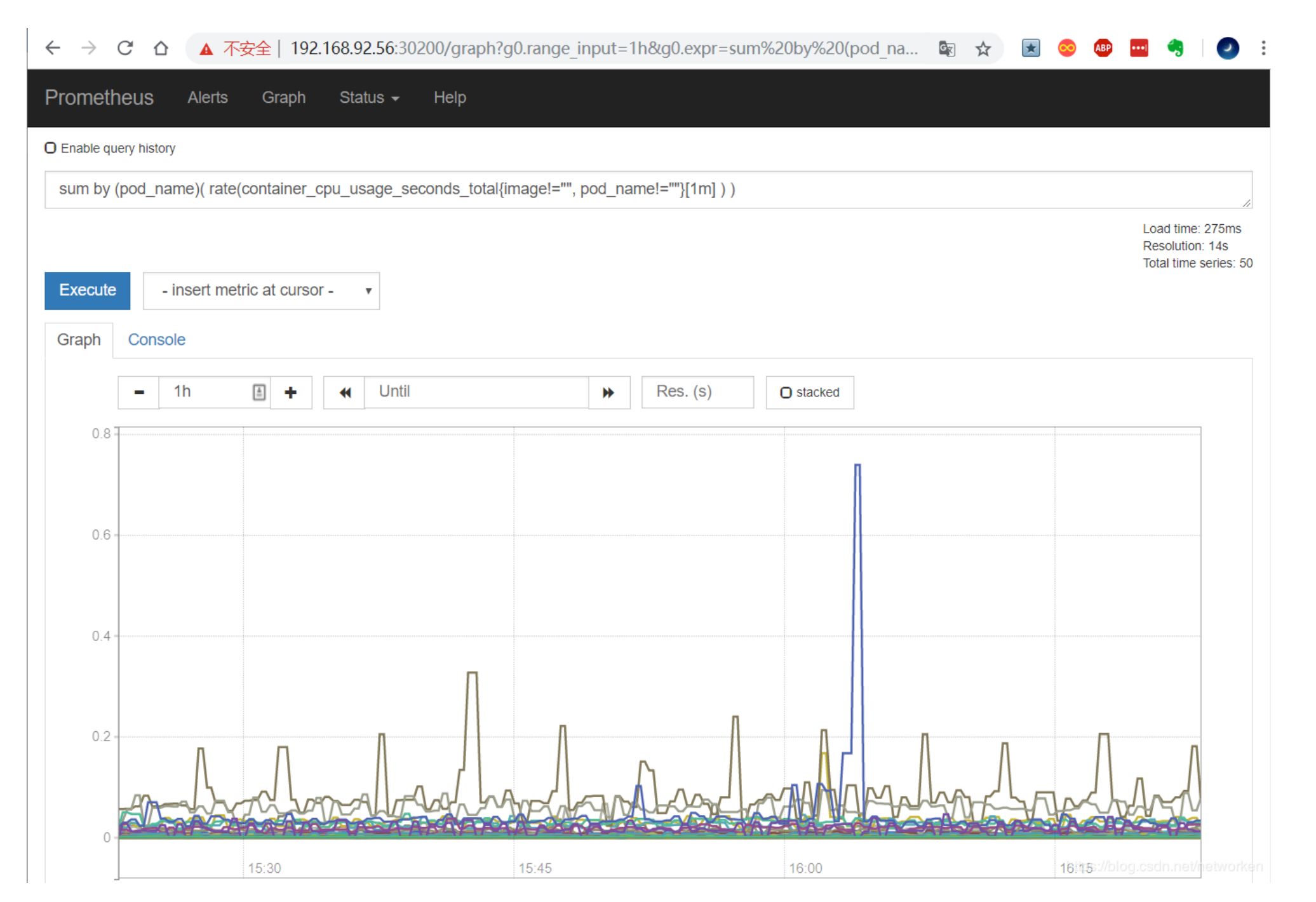
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常。接下来我们就可以部署 grafana 组件,实现更友好的 webui 展示数据了。
访问 grafana:
查看 grafana 服务暴露的端口号:
如上可以看到 grafana 的端口号是 30100,浏览器访问 http://MasterIP:30100,用户名密码默认 admin/admin。

修改密码并登陆
添加数据源 grafana 默认已经添加了 Prometheus 数据源,grafana 支持多种时序数据源,每种数据源都有各自 的查询编辑器
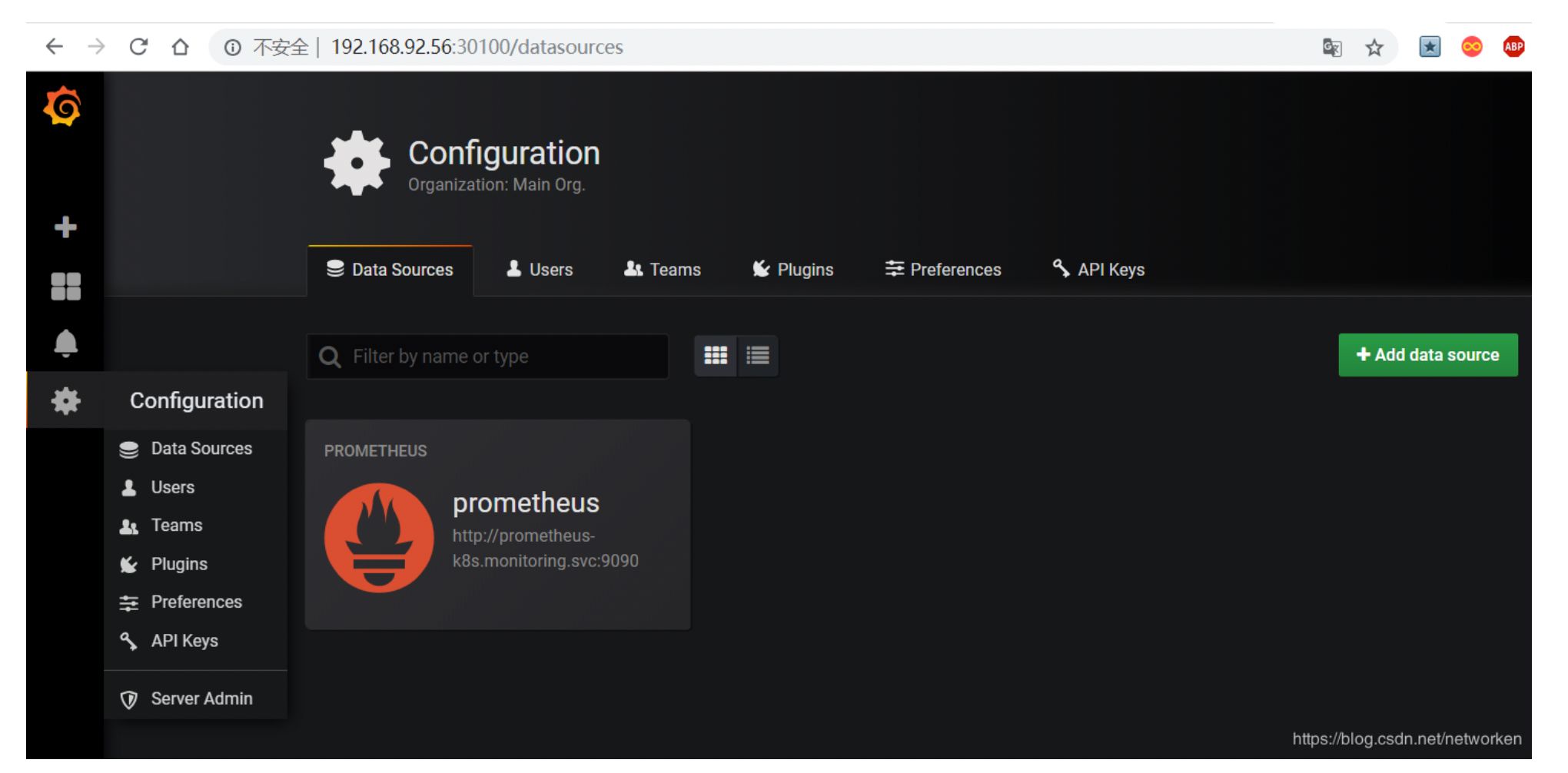
Prometheus 数据源的相关参数:
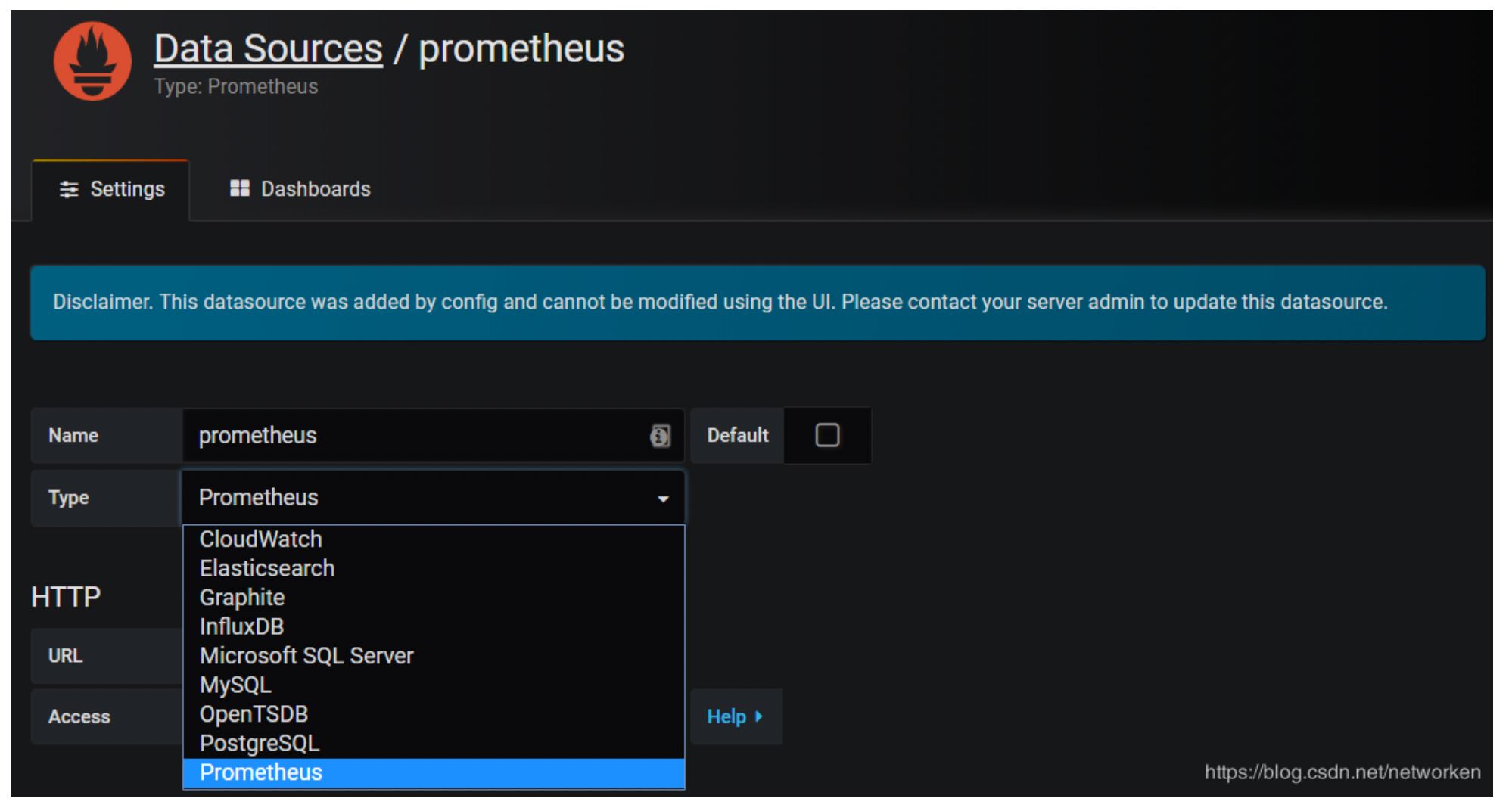
目前官方支持了如下几种数据源:
- 若无法正常加载, 请点击查看 PDF 网页版本: 部署 prometheus.pdf
5、部署 EFK 平台
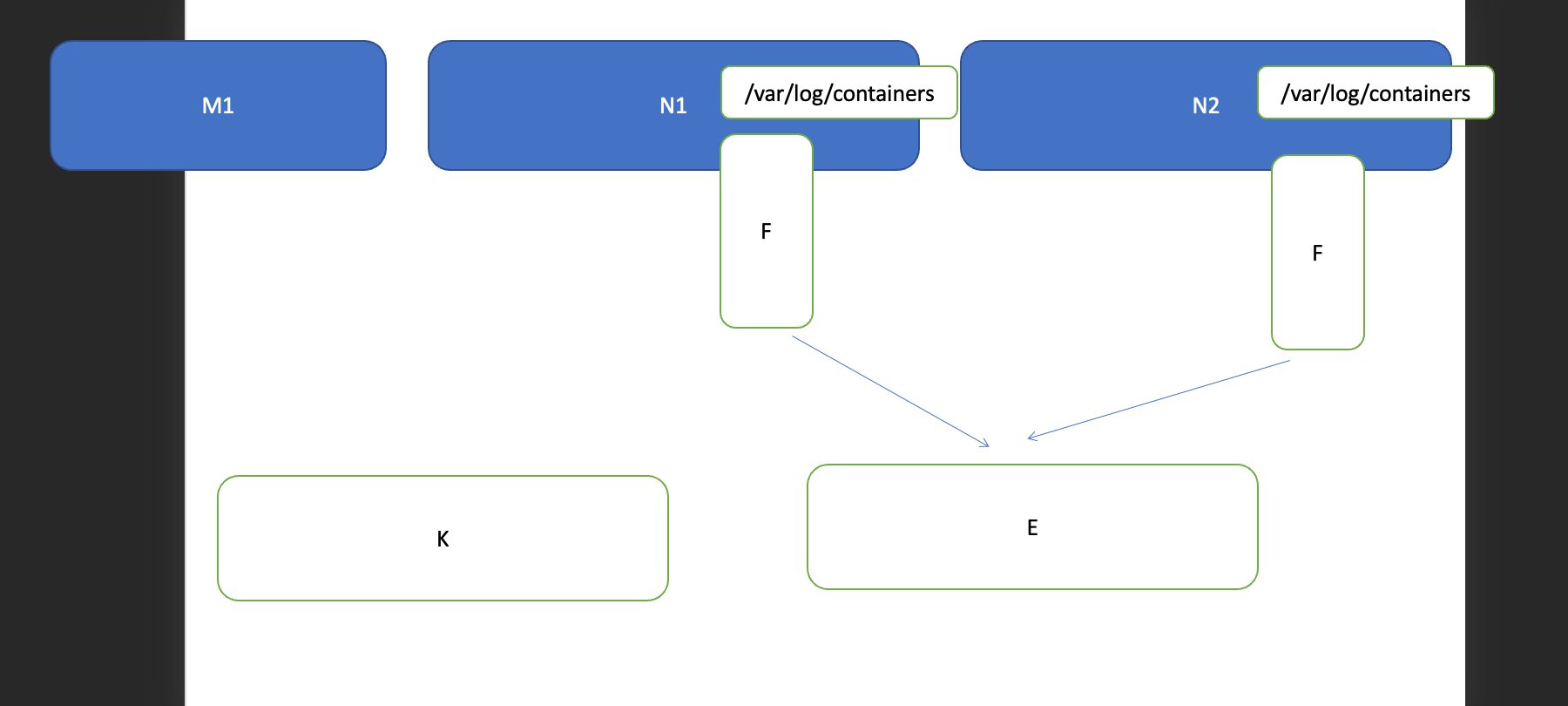
添加 Google incubator 仓库
部署 Elasticsearch
部署 Fluentd
部署 kibana
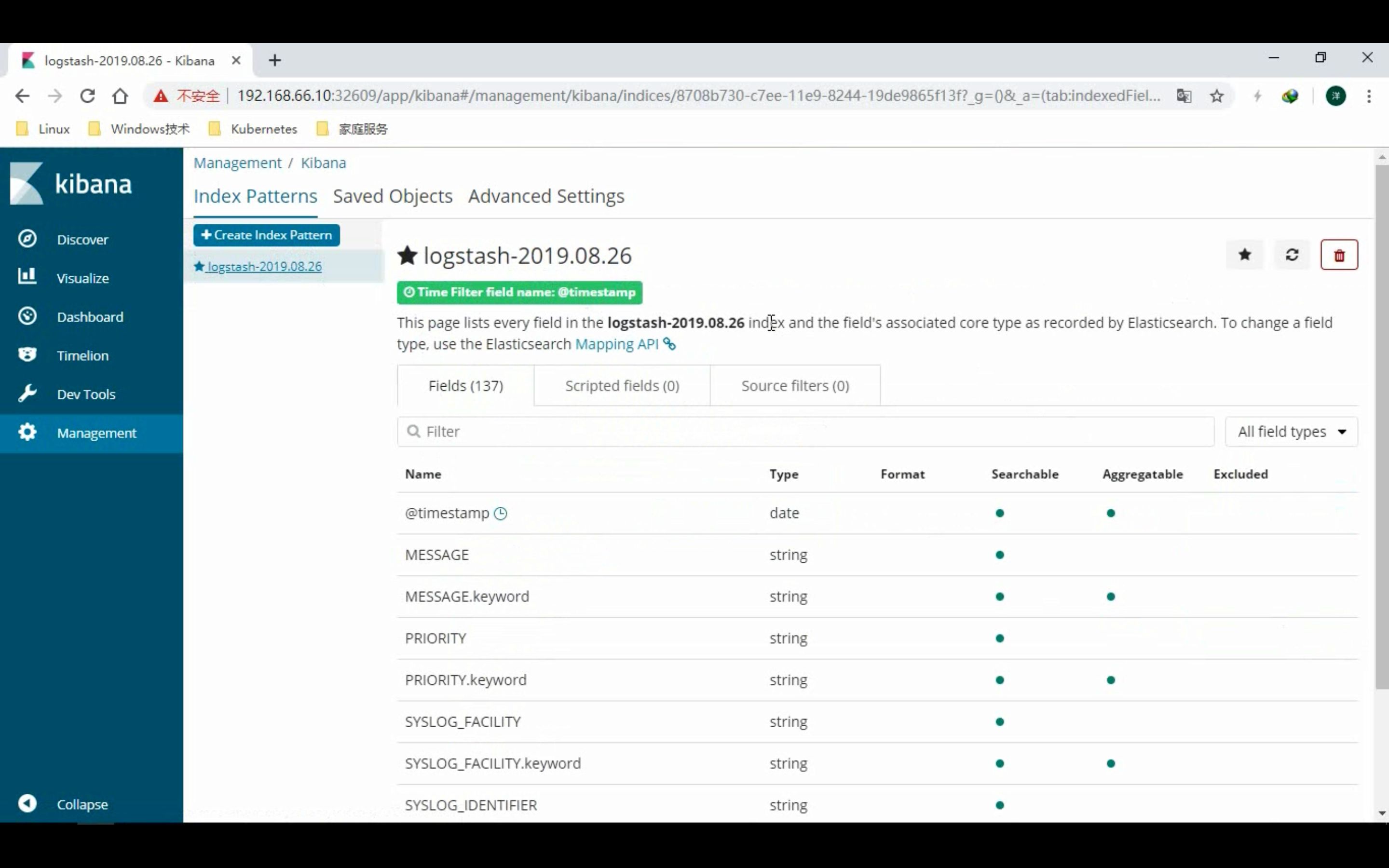
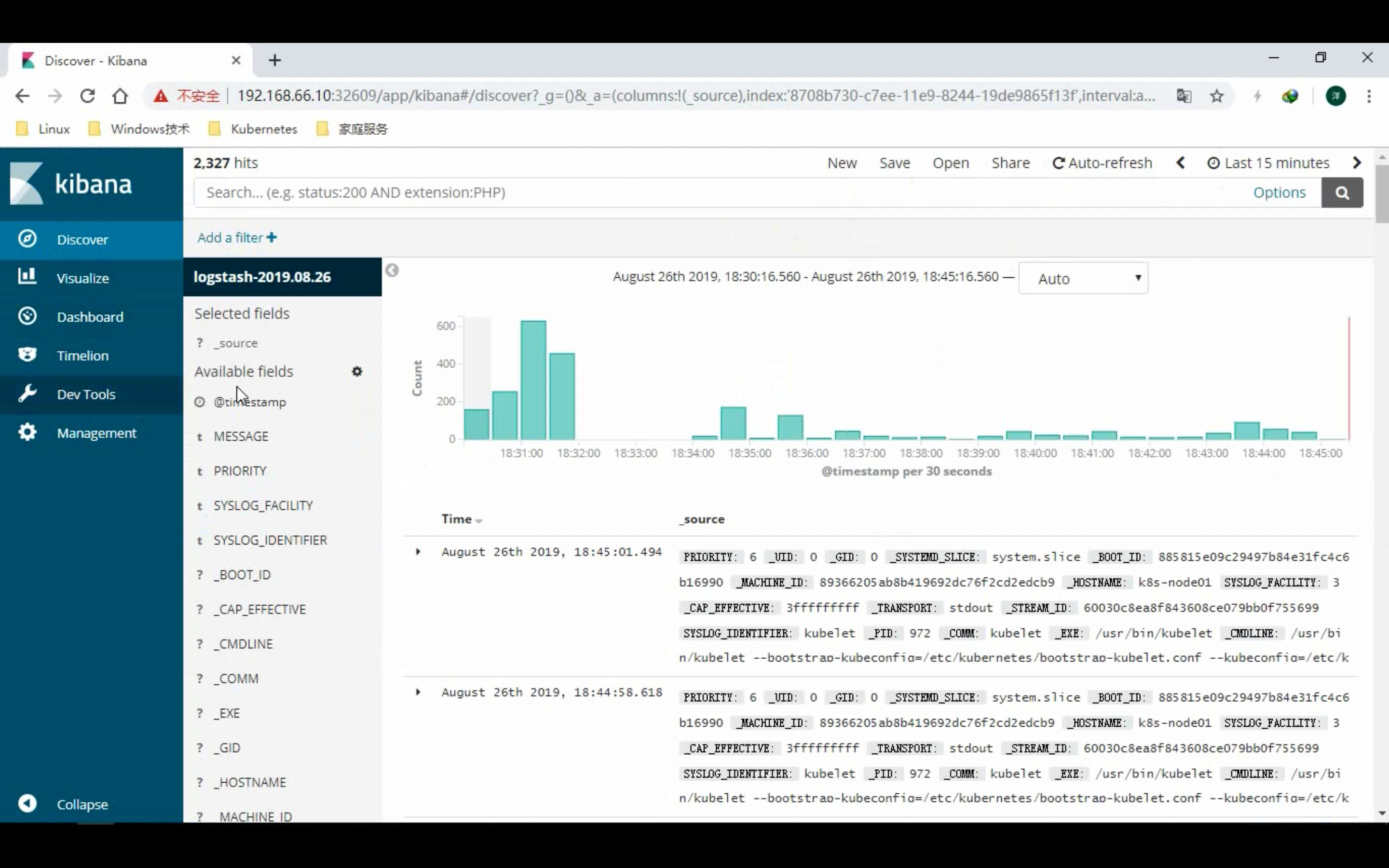
- 若无法正常加载, 请点击查看 PDF 网页版本: 部署 EFK 平台.pdf






